Why degenerate feedback loops need to be urgently addressed when operating machine learning models.
Predictive models are rarely static — operationalized models typically have an update cadence. At Mobilewalla, for instance, our models are updated every 30–180 days. At the end of each update period, the model is revised based on assessing the fidelity of its output since the last update. This is an important component of standard model maintenance practice, and is known as the feedback loop.
A degenerate feedback loop (DFL) occurs when this prior output unfairly impacts future outcomes. My favorite explanation of DFL is in Chip Hyuen’s lecture notes from the CS329S (ML Systems Design) class she teaches at Stanford (found here). To illustrate DFLs let me quote a passage directly from there: imagine you build a system to recommend to users songs that they might like. The songs that are ranked high by the system are shown first to users. Because they are shown first, users click on them more, which makes the system more confident that these recommendations are good. In the beginning, the rankings of two songs A and B might be only marginally different, but because A was originally ranked a bit higher, A got clicked on more, which made the system rank A even higher. After a while, A’s ranking became much higher than B. Degenerate feedback loops are one reason why popular movies, books, or songs keep getting more popular, which makes it hard for new items to break into popular lists.
DFLs have been studied widely in the context of recommender systems. In recent times, as the notions of fairness and bias in Machine Learning have become popular (see here for a tutorial), DFLs in particular have been identified as a key driver of ML bias [1]. However, other than in certain specialized contexts, such as models that drive public/social services (e.g., crime prediction and wealth prediction across neighborhoods), fairness, and therefore DFLs, have not made it into the mainstream. Most data science practitioners who are building models that drive commercial outcomes do not, typically, prioritize handling DFLs in their modeling workflow. If a model ended up being fairness challenged, as long as it was providing outputs with acceptable predictive accuracy, most modelers and MLOps professionals would not be overly concerned. This lack of concern is also reflected in software utilities commonly employed in model building, where features for preventing DFLs are not offered. In summary, the phenomenon of degenerate feedback loops, and the consequent unfairness in models, have not yet been prioritized as issues of significant practical importance for data scientists at large.
With this context, I come to the main topic of this article: why this perspective needs to change. It turns out while we can live with some degree of unfairness in most models, there is another, much more pressing practical problem that occurs as a result of DFLs that negatively impacts the quality of prediction — outcome starvation. We first explain this phenomenon and then provide two real world examples to illustrate its scope.
What is Outcome Starvation?
Any predictive model must pass three tests to be practically useful:
1. Are its predictions accurate beyond acceptable thresholds?
2. Is the model resilient?
3. Does it produce outcomes at a meaningful scale?
The first two are widely understood, but the third will be new to most readers — we’ve never seen it discussed in literature. To appreciate this issue, consider the classification problem in machine learning, where the goal of the model is to map inputs into a number of pre-determined buckets, or classes. Classification constitutes, the widest class of practical problems in machine learning — significant numbers of practical predictive problems reduce to the classification scenario, as we show in the table below.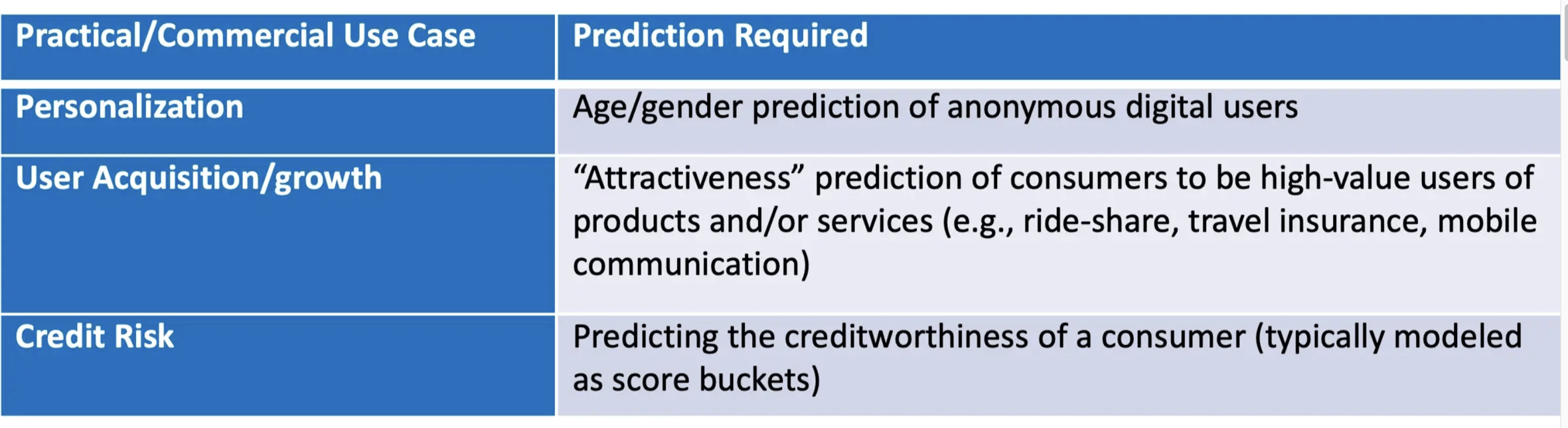
Classification Scenarios
In each case above, the model outcome (Prediction Required column) critically informs the relevant business process (Practical/Commercial Use Case column). Not only does the model need to be resilient, and produce accurate predictive outcomes, those outcomes need to occur at commercially meaningful volumes as well. Take the personalization use case above, and consider an e-commerce website. Once an anonymous user lands at this property, a ML model predicts the user’s demographics so that the ensuing engagement can be personalized. Assume this model follows a pre-determined update cadence, and is resilient. Further assume its outcomes are of acceptable predictive fidelity, e.g., it predicts gender with a 80%+ accuracy. However, for each input into the model, it can successfully classify only 10%. In other words, for each anonymous user who shows up, the model can ascertain their age/gender only 10% of the time with adequate confidence. Clearly, in spite of being resilient, and highly accurate, the model is not useful because it does not produce outcomes at a scale meaningful enough to drive the use case it supports. In this case, the model is outcome starved. At Mobilewalla, my colleagues and I have constructed models that support a wide range of industries and use cases — subscriber churn in telcos, high-value user acquisition in ride-share and food delivery, creditworthiness prediction in “Buy Now Pay Later” (BNPL) companies, stock/inventory prediction in CPG to name just a few — where we find that outcome starvation is a widely occurring phenomenon. Over 50% of the 120+ models we have in production turn outcome starved with time. Interestingly, like resilience, outcome starvation is a “progressive disease” — models never start out starved, but become that way with time. And, coming to the crux of this article, the primary cause of outcome starvation is the presence in degenerate feedback loops (DFL).
How Degenerate Feedback Loops cause Outcome Starvation
We now provide two real-world examples of how DFLs cause outcome starvation. In these we have direct participation in both building and operating the models involved.
Example 1: High-Value User Acquisition in Ride-Share
A major operating cost of ride-share companies is user acquisition. Yet, the likelihood of an acquired user turning into a “customer of value” is low. Based on our experience in working with a number of global ride-share providers, only 12–14% of acquired users turn into high-value customers (HVCs). As a result, these companies devote a considerable amount of data science resources to develop models of ride-share spend propensity. These models, given a prospect (and her characteristics) as input, return a “spend propensity score” as output. This score represents the likelihood of the prospect turning into a HVC. Using these scores, providers attempt to discriminate among a large prospect pool by attempting to preferentially acquire those users who are more likely to turn into HVCs. These models are critical to these providers — even a favorable swing of a percent or two in the HVC proportion in the acquired pool can result in hundreds of millions of dollars in additional top-line revenue annually.
Let’s now consider an instance of such a model. More specifically, let’s consider the predictive consumer features that anchor this model. While there are a number of such characteristics, it turns out that one with a high predictive power is Prospects Observed at Non-home Airports on 10+ occasions in the past 90 days — let’s refer to this as OBSGT10 for short. This is a real-world predictor that we’ve found of great practical use in these models. To illustrate the effect of DFL on this model, further assume that OBSGT10 is the most predictive feature in our model. This gets reflected via the “feature weight” in the model function — OBSGT10 starts out with marginally higher weight than a number of other features. As the model runs, it slightly prioritizes (as it is meant to do) prospects who satisfy OBSGT10, but pays attention to the other features as well. All goes well — the model produces expectedly good results — and drives up the ROI of user acquisition.
When model update time comes around, the new training set, now imbued with feedback from the previous cycle, has slightly more users who satisfy OBSGT10 than the original training set, and this time around the OBSGT10 feature is weighted a shade higher than its previous incarnation. This cycle continues, and soon enough, OBSGT10 has significantly more weight than its cohorts and the model turns significantly OBSGT10 biased — it is greedy for this feature in the prospect set. In fact, in the real world, we’ve seen feature sets change when this occurs — attributes that had slightly less weight in the beginning but were perfectly fine predictors, start dropping out of the feature set altogether.
Now we come to the crux of the problem — our model soon runs out of prospects who satisfy OBSGT10 in its target pool and in its altered state, can no longer power acquisition sets of meaningful scale. Note though, that in its original incarnation, when first operationalized, it was blessed with a wide variety of features that would still be driving perfectly acceptable scales. However, due to the DFL caused by OBSGT10, it eventually became outcome starved.
Example 2: Assessing applicant credit risk in Buy-Now-Pay-Later (BNPL) companies
We now focus on an entirely different use case in a completely different industry sector.
BNPL companies are a significant class of fintech firms, that have primarily evolved in emerging markets to address the situation created via the confluence of two societal phenomena:
· Rise of the “mass affluent”
· Lack of traditional credit footprint (credit card possession, credit history) in a majority of the mass affluent
In India for example, out of a 250+ million middle class, there are only about 57M credit cards (https://www.statista.com/statistics/1203267/india-number-of-credit-cards/ in 2021).
BNPL providers offer credit to consumers outside the traditional credit umbrella. Because most of these consumers do not possess a credit score, or the primary data needed to create one, BNPLs rely on creating their own credit risk models using machine learning. These models, given a prospect (and her characteristics) as input, return a “creditworthiness score” as output. These models are critical to these providers, representing the backbone of their underwriting strategy.
As in the previous example, let’s consider the predictive features that anchor credit risk models. Because traditional credit data is not available for a typical loan applicant, features are engineered from “alternative data”. One with a particularly high predictive power is Resides in Households where the average value of phone handset exceeds $Threshold (¹) — let’s refer to this as HHPHVAL for short. Following exactly the same model operations and feedback sequence described in Example 1, a degenerate feedback loop is created with HHPHVAL, causing this feature to be unfairly overweighted after a few update cycles. As a result, consumers who satisfy this feature get prioritized, and soon volume of underwritable applications slows to a trickle, as there are only so many households with high enough HHPHVAL. The model is now outcome starved.
Summary
DFLs are regarded as a primary cause of fairness and bias issues in ML models, but have not received significant attention from practitioners, as most data scientists building commercial models are willing to live with some degree of bias. However, one outcome of DFLs and the resulting unfairness is outcome starvation, which is a substantive practical diminisher of the utility of ML models, that are otherwise of high quality. Surprisingly this phenomenon has not received much attention in the literature though, at least in our experience, its occurrence is widespread. In this article, I introduced the notion of outcome starvation, and its relationship to DFL. In a future article, I will discuss how Mobilewalla is using Anovos, an open-source feature engineering library, to address outcome starvation by reducing the effect of DFLs.
[1] Dana Pessach & Erez Shmueli, A Review on Fairness in Machine Learning, Computing Surveys, Volume 55I(3), April 2023, pages 1–44
(¹) The value of $Threshold differs across geographies. In our models, it is instantiated at $400 in Indonesia and $225 in India